3. Data Manipulation
In this article, we will discuss four traditional data manipulation problems in SQL / Pandas. They are from
3.1: https://leetcode.cn/problems/nth-highest-salary/
3.2: https://leetcode.cn/problems/rank-scores/
3.3: https://leetcode.cn/problems/rearrange-products-table/
3.4: https://leetcode.cn/problems/calculate-special-bonus/
In our article, we won’t use the same data in these question. We’ll use a more simpler one to illustrate the functions.
3.1 TopK & n-th largest
TopK means selecting top k rows according to some rules from the table. n-th largest means selecting the just n-th largest row according to some rules from the table
3.1.1 MySQL
To select some first couple of rows from the table, you can use the LIMIT keyword. LIMIT M, N will select from M row (0-index), a total of N rows. See the following example and explanation.
1 | -- table is |
Therefore, it would be quite easy to implement the TopK and n-th largest. For example, if we want to find top 2 grade students and the 2nd highest student in this table:
1 | -- find top 2 grade students |
3.1.2 Pandas
In pandas, we have the method pd.DataFrame.nlargest(N, col_name) to find the top N rows. Note that, after executing this method, the result table is already sorted descending. Access the last one row will just be the n-th largest.
1 | # the df is |
3.2 rank, dense_rank
This question requires us to build a dense rank. That is, when there are rows that “score” are same, they should both appear and they should have the same score. Fortunately, we have built-in functions to help us achieve that.
3.2.1 MySQL
There is a function called DENSE_RANK(), which can be used to create a new column based on the ranking information.
1 | -- The table is: |
Usually, our ranking is not like this: if we have two 4.0 students, the rank of 3.85 student should be 3, not 2. The RANK() functions helps in this case:
1 | SELECT S.score, RANK() OVER ( |
3.2.2 Pandas
In pandas, such operation is quite easy: we have the pd.Series.rank() function. This function has multiple parameters. The most important two are method and ascending. When method is 'dense', it performs as dense_rank. When method is min, it is the common ranking (meaning that when we have multiple same score, we should take minimum rank for all of them). ascending controls whether 1 is assigned to highest or lowest.
1 | # scores is: |
3.3 row to column conversion
3.3.1 MySQL
The idea is quite simple as illustrate below:
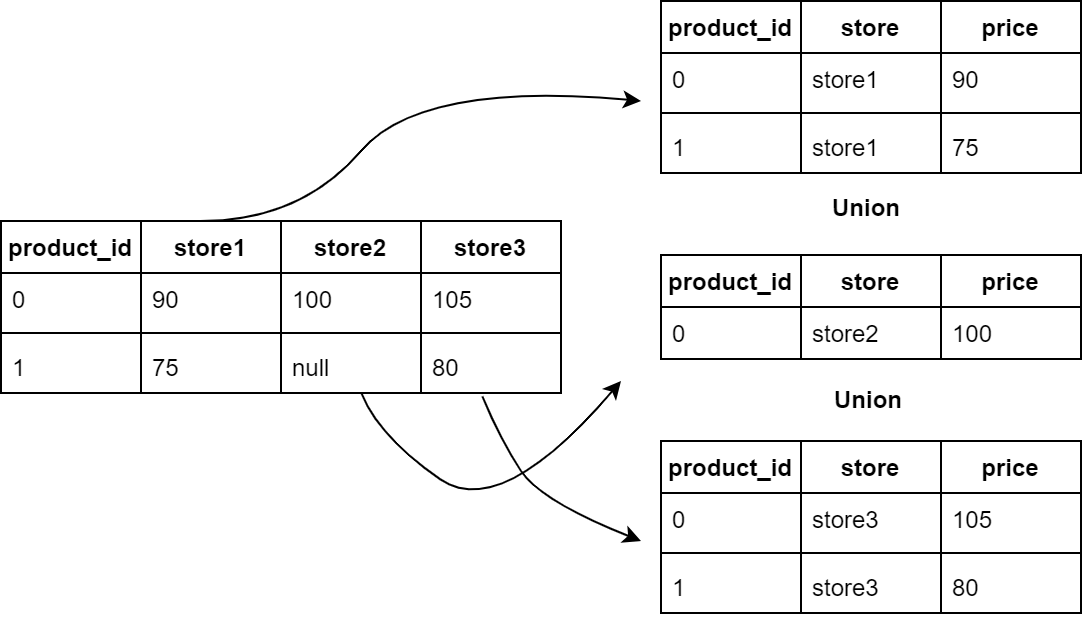
First, we extract each column to form a new table corresponding to each store. Then, we concatenate (“Union”) three tables together. Note that when we are extracting the table, we should remove “null” rows.
Follow this idea, our implementation would be relatively easy:
1 | select product_id, 'store1' as store, store1 as price from Products where store1 is not null |
3.3.2 Pandas
In pandas, you can use the similar idea as listed in the above subsection. But Pandas provides more powerful tools, pd.melt, which helps us to convert wide (row) format into long (column) format:
1 | Input: |
The id_vars is the identifier column (will not be changed), value_vars is the columns to be converted. var_name is the new column name from converted columns.
1 | df = products.melt( |
3.4 Conditional operator
The question requires us to set each value according to a predicate. Such basic requirement is well-supported by the MySQL and Pandas.
3.4.1 MySQL
In MySQL, if(cond, true_value, false_value) is a good helper. This should appear after SELECT.
1 | SELECT |
The second column, bonus, entry would be the same value of salary if the condition is satisfied, otherwise it is 0. For the condition, the second is the grammar of regular expression, asserting true only when name does not start with M. You may also use name NOT LIKE 'M%' for the second condition.
3.4.2 Pandas
In pandas, we can use the pd.DataFrame.apply function to achieve this. The apply function accepts a function, f(x), which x is the “current” row. Based on the information on that row, it returns a value. For example, in this question, the condition is “the employee is an odd number and the employee’s name does not start with the character 'M'. “
1 | # judge function |
1 | # Sample input: |
Which satisfies the requirement.