In the section 6 to 9, we’ll investigate how to use torch.autograd.Function to implement the hand-written operators. The tentative outline is:
- In the section 6, we talk about the basics of
torch.autograd.Function. The operators defined bytorch.autograd.Functioncan be automatically back-propagated. - In the last section (7), we’ll talk about mathematic derivation for the “linear layer” operator.
- In this section (8), we talk about writing C++ CUDA extension for the “linear layer” operator.
- In the section 9, we talk details about building the extension to a module, as well as testing. Then we’ll conclude the things we’ve done so far.
Note:
- This blog is written with following reference:
- For how to write CUDA code, you can follow official documentation, blogs (In Chinese). You can search by yourself for English tutorials and video tutorials.
- This blog only talk some important points in the matrix multiplication example. Code are picked by pieces for illustration. Whole code is at: code.
Overall Structure
The general structure for our PyTorch C++ / CUDA extension looks like following:
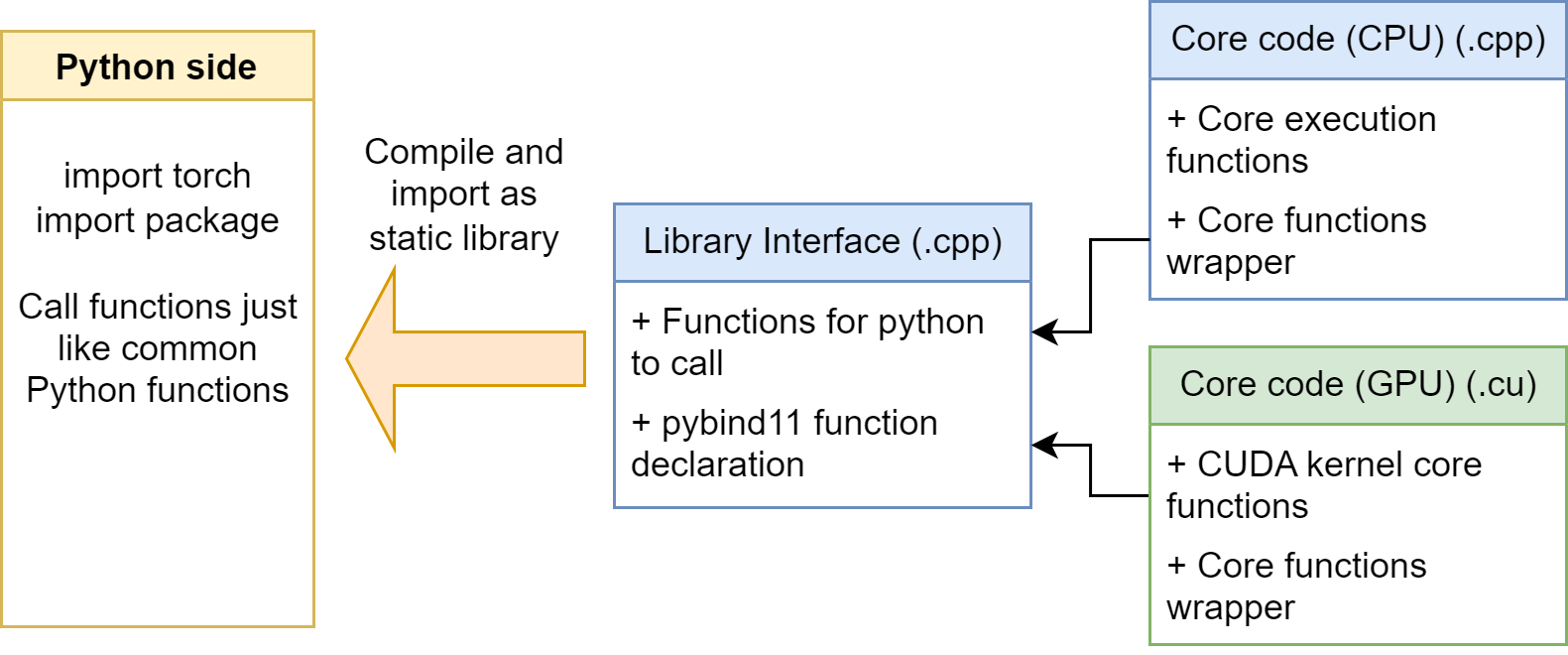
We mainly have three kinds of file: Library interface, Core code on CPU, and Core code on GPU. Let’s explain them in detail:
Library interface (.cpp)
- Contains Functions Interface for Python to call. These functions usually have Tensor input and Tensor return value.
- Contains a standard pybind declaration, since our extension uses pybind to bind the C++ functions for Python. It indicates which functions are needed to be bound.
Core code on CPU (.cpp)
- Contains core function to do the calculation.
- Contains wrapper for the core function, serves to creating the result tensor, checking the input shape, etc.
Core code on GPU (.cu)
- Contains CUDA kernel function
__global__to do the parallel calculation. - Contains wrapper for the core function, serves to creating the result tensor, checking the input shape, setting the launch configs, launching the kernel, etc.
- Contains CUDA kernel function
Then, after we finishing the code, we can use Python build tools to compile the code into a static object library (.so file). Then, we can import them normally in the Python side. We can call the functions we declared in library interface by pybind11.
In our example code, we don’t provide code for CPU calculation. We only support GPU. So we only have two files (src/linearops.cpp and src/addmul_kernel.cu)
Pybind Interface
This is the src/linearops.cpp file in our repo.
1. Utils function
We usually defines some utility macro functions in our code. They are in the include/utils.h header file.
1 | // PyTorch CUDA Utils |
The third macro will call first two macros, which are used to make sure the tenser is on the CUDA devices and is contiguous.
The last macro performs ceil division, which are often used in setting the CUDA kernel launch configurations.
2. Interface functions
Benefited by pybind, we can simply define functions in C++ and use them in Python. A function looks like
1 | torch::Tensor func(torch::Tensor a, torch::Tensor b, int c){ |
is relatively same as the Python function below.
1 | def func(a: torch.Tensor, b: torch.Tensor, c: int) -> torch.Tensor |
Then, we can define our matrix multiplication interface as below. Note that we need to implement both the forward and backward functions!
- forward
Check the input, input size, and then call the CUDA function wrapper.
1 | torch::Tensor matmul_forward( |
- backward
Also check the input, input size, and then call the CUDA function wrapper. Note that we calculate the backward of A * B = C for input matrix A, B in two different function. So that when someday we don’t need to calculate the gradient of A, we can just pass it.
The gradient function derivation is mentioned in last section here.
1 | /* Backward for A gradient */ |
3. Binding
At the last of the src/linearops.cpp, we use the following code to bind the functions. The first string is the function name in Python side, the second is a function pointer to the function be called, and the last is the docstring for that function in Python side.
1 | PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) { |
CUDA wrapper
This is the src/addmul_kernel.cu file in our repo.
The wrapper for matrix multiplication looks like below:
1 | torch::Tensor matmul_cuda(torch::Tensor A, torch::Tensor B) { |
And here, we’ll talk in details:
1. Get metadata
Just as the tensor in PyTorch, we can use Tensor.size(0) to axis the shape size of dimension 0.
Note that we have checked the dimension match at the interface side, we don’t need to check it here.
2. Create output tensor
We can do operation in-place or create a new tensor for output. Use the following code to create a tensor shape m x p, with same dtype / device as A.
1 | auto result = torch::empty({m, p}, A.options()); |
In other situations, when we want special dtype / device, we can follow the declaration as below:
1 | torch::empty({m, p}, torch::dtype(torch::kInt32).device(feats.device())) |
torch.empty only allocate the memory, but not initialize the entries to 0. Because sometimes, we’ll fill into the result tensors in the kernel functions, so it is not necessary to initialize as 0.
3. Set launch configuration
You should know some basic CUDA knowledges before understand this part. Basically here, we are setting the launch configuration based on the input matrix size. We are using the macro functions defined before.
1 | const dim3 blockSize = dim3(BLOCK_SIZE, BLOCK_SIZE); |
We set each thread block size to 16 x 16. Then, we set the number of blocks according to the input size.
4. Call the cuda kernel launcher
Unlike normal cuda programs, we use ATen‘s function to start the kernel. This is a standard operation, and you can copy-paste it to anywhere.
1 | AT_DISPATCH_FLOATING_TYPES(A.type(), "matmul_cuda", |
This function is named
AT_DISPATCH_FLOATING_TYPES, meaning the inside kernel will support floating types, i.e.,float (32bit)anddouble (64bit). Forfloat16, you can useAT_DISPATCH_ALL_TYPES_AND_HALF. For int (int (32bit)andlong long (64 bit)and more, useAT_DISPATCH_INTEGRAL_TYPES.The first argument
A.type(), indicates the actual chosen type in the runtime.The second argument
matmul_cudacan be used for error reporting.The last argument, which is a lambda function, is the actual function to be called. Basically in this function, we start the kernel by the following statement:
1
2
3
4
5
6matmul_fw_kernel<scalar_t><<<gridSize, blockSize>>>(
A.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
B.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
result.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
m, p
);matmul_fw_kernelis the kernel function name.<scalar_t>is the template parameter, will be replaced to all possible types in the outsideAT_DISPATCH_FLOATING_TYPES.<<<gridSize, blockSize>>>passed in the launch configuration- In the parameter list, if that is a
Tensor, we should pass in the packed accessor, which convenient indexing operation in the kernel.<scalar_t>is the template parameter.2means theTensor.ndimension=2.torch::RestrictPtrTraitsmeans the pointer (tensor memory) would not not overlap. It enables some optimization. Usually not change.size_tindicates the index type. Usually not change.
- if the parameter is integer
m, p, just pass it in as normal.
5. Return the value
If we have more then one return value, we can set the return type to std::vector<torch::Tensor>. Then we return with {xxx, yyy}.
CUDA kernel
This is the src/addmul_kernel.cu file in our repo.
1 | template <typename scalar_t> |
- We define it as a template function
template <typename scalar_t>, so that our kernel function can support different type of input tensor. - Usually we’ll set the input
PackedTensorAccessorwithconst, to avoid some unexpected modification on them. - The main code is just a simple CUDA matrix multiplication example. This is very common, you can search online for explanation.
Ending
That’s too much things in this section. In the next section, we’ll talk about how to write the setup.py to compile the code, letting it be a module for python.